Region features for YOLO architecture
Introduction
Scaled-YOLOv4 is an Object Detector, a machine learning model capable of detecting the location and the nature of the objects depicted inside an image.
Its grandfather, YOLO, represented a breakthrough in the field of computer vision, flooded at the time (2016) by very big and slow detectors.
What allowed YOLO to stand out was its very low inference time that, for the first time, made it possible to work in real-time.
In the following years, a lot of effort has been put to improve the original architecture, with the succeeding versions, YOLOv2 (2016), YOLOv3 (2018), and YOLOv4 (2020).
What makes YOLO faster than the other architectures is the ability to produce the final detections in a single stage, directly from the raw pixels while traditional Object Detectors rely on two different stages.
Two-Stages Detectors
In Two Stages detectors, feature maps are produced with a backbone network, an image classification network, pretrained on ImageNet.
Then the regions (where the objects are supposed to be) are proposed via a region proposal network and their coordinates are used to ROI pool the feature maps to produce per-region features, then used to predict the object class (and attribute in some cases).
Region of interest pooling (ROI pooling) is a specific kind of pooling that allows obtaining fixed-size features, starting from a feature map and the coordinates of a region. Traditional pooling is an operation widely used to decrease the dimensionality of the feature maps. It usually operates with a fixed-sized kernel (ie. 2x2 or 3x3) that slides over the entire feature map, aggregating the results according to the type of pooling (max-pooling takes the maximum of the values inside the kernel, average pooling takes the average). It works independently on all the channels. ROI pooling is particularly useful because it can operate on a region of the feature map and produces a fixed-sized output regardless of the dimension of the proposed regions, which for an object detector could vary significantly. It works by dividing the region into a grid of subregions of the specified output dimension. Then max-pooling is applied on the feature maps, following the grid subregions previously considered.

One-Stage Detectors
One-stage Object Detectors as YOLO instead are able to produce the inference just by looking at the image once (as the name suggests). This mechanism allows the model to work in real-time with very low latency.

Bounding boxes coordinates are regressed directly from the whole input image along with an objectness score that indicates how much the model is confident that in that box there is actually an object. The image is divided into an S × S grid. If an object falls into a grid cell, that grid cell is responsible for its detection.

Each grid cell regresses B bounding boxes and, for each of them, predicts also the class probabilities for C object classes (C = 80 classes in the original architecture).
Motivation
Notice that, while Two-Stages networks rely on computed per-region features, One-Stage networks regress the predictions directly from the same aggregated feature maps.
The lack of such dedicated features can be a problem for bigger architectures that heavily make use of them. Object Detectors are in fact a crucial component for a multitude of Visual Understanding and Generation tasks such as Image Retrieval, Image Captioning, and Visual Question Answering.
To be able to solve these tasks, the models usually start from the output of an Object Detector applied to the input image.
In these cases, having sets of features specifically related to each object is such a great advantage that, despite being much slower, Two-Stage models are still the most common choice.
Two examples are VinVL, a powerful Image Captioning model using ResNeXT, and TERN, a very scalable Image Retrieval model using Faster R-CNN. Both ResNeXT and Faster R-CNN produce per-region features that are needed by the respective architectures.
Replacing such Object Detectors with One-Stage solutions could significantly reduce inference time but the lack of dedicated features makes those models incompatible with the aforementioned architectures.
One possible way to solve this incompatibility is to force YOLO to produce per-region features. This is not straightforward since there is no layer from which it’s possible to extract some region-specific information. For this reason, altering the architecture is required.
In the following sections, TERN architecture will be taken into consideration with the objective of replacing the original Faster R-CNN Object Detector with Scaled-YOLOv4 to increase speed.
The architecture
Starting from YOLOv4, a technique called Cross Stage Partial Network (CSP) is applied to reduce the number of computations. The main idea behind CSP is that the amount of computation of a given CNN stage can be reduced by splitting the feature maps. One part is fed to the actual stage, followed by a transition layer. The transition layer output is then concatenated with the remaining part of the input feature maps. The resulting architecture is called Scaled-YOLOv4.
Macroscopically, Scaled-YOLOv4 is composed of the backbone, Darknet-53,
consisting of 5 downsample blocks, the neck, responsible for aggregating features coming from different blocks of the backbone and three heads, that, applied at different stages on the network, starting from the neck’s output, detect different-sized objects.
Inside the head, the image is divided into an S ×S grid and for each grid cell, B bounding boxes are regressed. So, considering C the number of classes, the dimension of the output vector is B × S × S × (5 + C).
Working on different stages of the network, each head has a different value of S, while B is fixed to 3 and C is fixed to 80. Fixing the values, the dimensions become 3 × S × S × 85. To match this shape, the last convolutional layer before the head is designed to produce a 255 × S × S vector that is then reshaped.

The idea
To force Scaled-YOLOv4 to produce region features, the last convolutional layer before the head is increased in size to produce a vector of dimension 3087 × S × S, then reshaped into 3 × S × S × 1029. The first 5 values of the last dimension are 4 coordinates and one objectness score as before, but instead of returning directly the 80 per-class probabilities, 1024 features are computed. Then those 1024 feature vector is fed to a linear layer responsible for the actual classification. In this way, with proper finetuning, the model is forced to produce a 1024 elements representation, specific for each region, since the region class is predicted solely on it. Those features are extracted and treated exactly as the Faster R-CNN ones.
The resulting model (TERN) needs to be finetuned to adapt the weights to the new features.
Both Scaled-YOLOv4 and TERN are finetuned on COCO dataset since it is both an Object Detection and Image Retrieval dataset.

Finetuning
Both the object detector and TERN need to be trained and training is done in two stages.
In the first stage, the Object Detector is finetuned on COCO to make the
model adapt to the architecture tweaks. All the weights with exception of the last convolutional layers before the heads and the added linear layers are transferred from the original model. Finetuning consists of 30 epochs with a batch size of 8, maximum image size of 640 pixels, SGD optimizer with an initial learning rate of 0.01, momentum equal to 0.937, and 5e-4 weight decay.
In the second stage, TERN is trained on COCO, feeding the precomputed feature vectors of the object detector along with the original captions. Notice that modified Scaled-YOLOv4 produces 1024 feature elements in contrast with the 2048 elements of Faster R-CNN. Therefore the first TERN layer of the visual branch is reduced in dimension.
The original TERN was trained on COCO dataset too, so pre-computed weights could still be useful as a starting point. For this reason, multiple experiments have been done, freezing different portions of the architecture while transferring the original weights. Training consists of 30 epochs with a batch size of 80, Adam optimizer with a learning rate equal to 2e-6. The experiments have been conducted with a single graphics card. The available cards were an Nvidia GeForce 1080Ti and an Nvidia GeForce Titan X. The former performs slightly better but the training times are comparable.
Further details on training times and model sizes are reported in the table below. The final architecture consists of 181 Million parameters, 58 Million for YOLO, and 123 Million for TERN.

Results
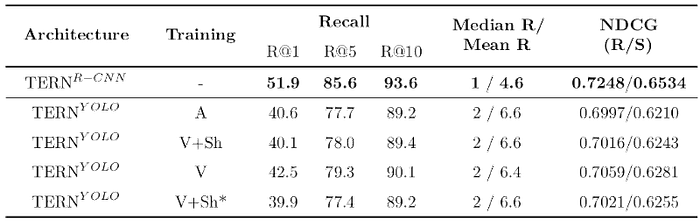
The Image Retrieval model TERN−YOLO is evaluated on the COCO 1k-testset.
The performance tests have been executed on an Nvidia 1080Ti on the same video.
The original model is still the best one. This can be evidence that the features produced by Faster R-CNN are better and more informative with respect to modified YOLO. This is somehow expected since Scaled-YOLO is not designed to produce region features and adapting such architecture resulted in sub-optimal representations. Moreover, YOLO is only trained on COCO while Faster R-CNN is also trained on VisualGenome, so the latter will probably recognize a wider variety of regions with respect to YOLO, limited on the 80 COCO classes, leveraging also the per-region attributes present on VisualGenome. Among TERN−YOLO results, better performances seem to be obtained while training only the visual branch, keeping intact the rest of the network. This suggests that TERN original weights were already well trained on the language side and needed no finetuning.

On the real-time performance side, it’s possible to notice the inference time difference between Two-Stages Object Detectors (Faster R-CNN) and One-Stage Object Detectors (Scaled-YOLOv4). TERN−YOLO is able to work around 10 times faster than TERN−R-CNN.
Conclusions
The results show how, switching to a Single Stage detector, TERN inference time is reduced by 10 times. Unfortunately, altering such model to produce them leads to a drop in metrics. Changing the finetuning strategy or the dataset could potentially fill the gap, reaching the original metrics while keeping the inference time boost.
From these experiments, it’s possible to conclude that there is room for improvement and that such architecture change could potentially be a possible solution to adapt Single Stage Detectors for models usually relying on Two Stages Detectors.
A big thank you goes to AddFor S.p.A. that made available the graphic cards required for the experiments.
